Can we simply apply existing off-policy methods to leverage offline data when learning online, without offline RL pre-training or explicit imitation terms that privilege the prior offline data? The primary objective of the authors is to answer this question. However, to do this, the authors had to solve three main problems.
- Expensive expert data from real robots
- Sparsity of reward signal in robotics
- Poor sample efficiency with offline data
There have been methods to address these problems with pre-training and imitation-term. Yet, they are not sample-efficient and require reliable data source and doing so is very expensive. On top of that, these algorithms are very sensitive to OOD(out-of-distribution) due to their learning dynamics.
With these challenges in mind, RLPD provides robustness in dataset quality and sample-efficiency. More precisely, RLPD can train with suboptimal data and expert data and even with off-policy data. The authors propose three distinct methods to mitigate these problems based on SAC(Soft Actor-Critic). These are called the “Symmetric Sampling”, “Layer Normalization”, and “Random Ensemble Distillation”.
Symmetric Sampling
Overall idea of symmetric sampling is extremely simple. It constructs each batch with 50% samples from the replay buffer and 50% from the offline data buffer. In spite of this simplicity, it resolves the OOD problem in a stable manner, alleviating the restriction of data with sub-optimal trajectories.
- Offline data: Expert Demonstration (small) + Sub-optimal trajectories (large) collected by sub-optimal policies.
Layer Normalization
Batch normalization normalizes each feature value through samples. Unlike batch normalization, layer normalization normalizes each sample’s values through layer outputs. To provide further clarification, layer normalization calculates mean and standard deviation from a sample’s activations across the layer’s outputs, rather than across a batch.
Through this method, RLPD can mitigate Q-value overestimation problem in OOD observations. This is because layer normalization constrains the Q-value within the weight norm, as shown below.
\(Q^*(s, a) = \sum_{s', r} p(s', r | s, a) \left[ r + \gamma \max_{a'} Q^*(s', a') \right]\)
Bellman optimal equation triggers Q-value overestimation
\(\begin{aligned}
\|Q_{\theta,w}(s, a)\| &= \|w^T \mathrm{relu}(\psi_\theta(s, a))\| \\
&\le \|w\| \|\mathrm{relu}(\psi_\theta(s, a))\| \le \|w\| \|\psi(s, a)\| \\
&\le \|w\| (\because Layer Norm)
\end{aligned}\)
Layer normalization constrains Q-values within the weight norm
Random Ensemble Distillation + High UTD(update-to-data) ratio
UTD means the number of updates per batch. As a result of high UTD, the algorithm can use data more efficiently, and it means more sample-efficient learning. Ironically, other studies have shown that it can lead to statistical overfitting (Li et al., 2022) due to repeated updates on the same samples. To ameliorate this, authors have suggested to use random ensemble distillation.
Random ensemble distillation addresses overfitting similarly to DDQN and TD3, by maintaining multiple value functions. In the context of random ensemble distillation, it maintains an ensemble of $E$ Q-models, randomly selects 2 for the update step, and averages all $E$ Q-models when updating the policy to estimate the true Q-value
RLPD(Reinforcement Learning with Prior Data) Algorithm

Green lines refer shared methods for all tasks and purple lines are task specific methods. The purple lines are optional and can be applied depending on the task.
As you can see in the pseudocode, the algorithm is a combination of SAC, TD3, and the features I introduced above. This incorporates the clipped double Q-learning from TD3 and entropy maximization from SAC.
Experiments
In the experiments, the authors tried to answer the following questions.
- Is RLPD competitive with prior work despite using no pre-training nor having explicit constraints?
- Does RLPD transfer to pixel-based environments?
- Does LayerNorm mitigate value divergence?
Let’s see the detailed results and the analysis.
RLPD’s competitiveness with prior data without pre-training nor explicit constraints?
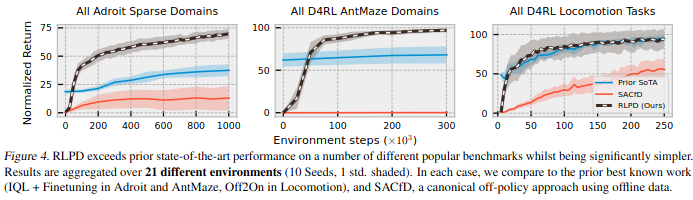
SACfD initializes the online replay buffer with the offline data
RLPD achieves 2.5$\times$ the performance on the sparse Adroit ‘Door’ task.
Does RLPD transfer to pixels?
V-D4RL (Lu et al., 2022), an offline dataset with only pixel observations.
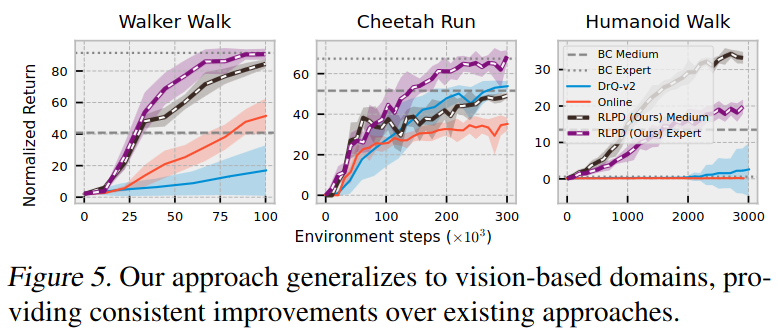
To evaluate the performance in pixel-based environments, they applied RLPD to V-D4RL(DeepMind Control Suite with visual observations only). In these environments, the authors proved that RLPD provides consistent improvements over online approaches, greatly improving over a BC baseline as well.
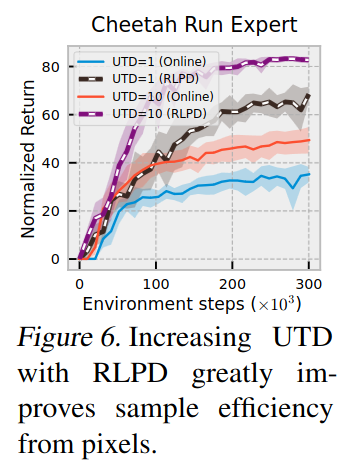
Also, they demonstrate a remarkable improvement in performance with the offline dataset and high UTD(update-to-data) ratio. It is worth noting that UTD=10 means 10 times updates per batch.
Does LayerNorm mitigate value divergence?
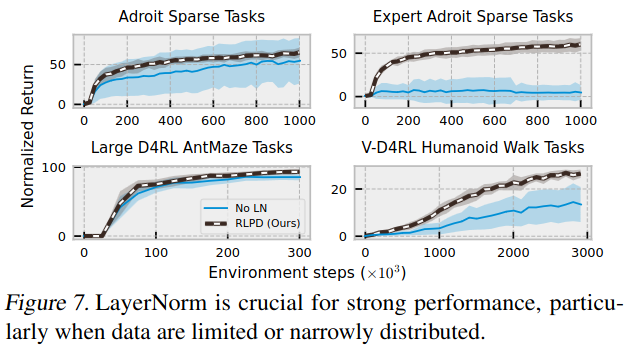
In Adroit domain, LayerNorm plays a crucial role for strong performance. Excluding LayerNorm escalates variance and reduces mean performance. In addition, in AntMaze and Humanoid Walk environments, LayerNorm diminishes excessive extrapolation.
References
- Ball, P. J., Smith, L., Kostrikov, I., & Levine, S. (2023). Efficient online reinforcement learning with offline data. In International Conference on Machine Learning (pp. 1577-1594). PMLR.